数据集缓存
为了提高数据集读取速度,有效缩短报表生成时间,产品为数据集添加了灵活的缓存机制。
实现原理
通过在内存中缓存频繁使用的数据集,可以把正常方式访问数据集时执行的基于慢速数据库连接的、大数据量原始表的过滤、关联、分组统计等操作,变为基于快速内存读取的、小数据量结果数据的简单查询。数据集缓存从如下三个方面提高了速度:
访问方式
从连接外部数据库,变为内存数据库查询。对高频次数据集查询作用明显。
数据量
从对原始表的大数据量进行操作,变为对过滤、统计后的缓存进行操作(根据缓存方式不同,缓存数据量或者等于最终查询结果集数据量,或者介于结果集数据量与原始数据表之间)。对原始表数据量较大的数据集作用明显。
操作
从对数据的过滤、关联、分组统计等复杂操作,变为对数据的简单查询(根据缓存方式不同,可能是直接读取或进行简单过滤)。对运算复杂的数据集作用明显。
当然,以上的几个因素可能在一个数据集上同时发挥作用,例如一个数据集操作复杂,访问频次又特别高,那样效果就更明显了。
两种缓存方式
根据实际应用场景中用户访问数据集的不同特点,我们提供了两种缓存方式:参数一致缓存,以及在缓存中过滤。二者的区别主要是对参数处理不同,前者在缓存前使用参数过滤数据,只缓存与参数匹配的数据,后者缓存与各种参数值匹配的数据,在读取缓存时再依据参数过滤数据,二者具体描述如下:
参数一致缓存
第一次访问数据集,创建缓存时,缓存当前参数得出的数据,再次访问数据集时,只有参数与创建缓存时的所有参数都一致,才算作缓存命中,直接返回缓存中的数据。该方式优点是缓存占用内存较少,缺点是如果各次访问参数变化较大,则不易命中缓存。因此,该方式适用于参数变化少,大量数据集访问集中在少数几个参数值的应用场景。
在缓存中过滤
第一次访问数据集,创建缓存时,缓存所有参数在所有可能取值情况下的数据合集,再次访问数据集时,不管参数值是多少,数据都一定在缓存中,但因为缓存中数据多于需要的数据,需要对数据进行二次过滤后返回,这也是”在缓存中过滤“这个名字的由来。该方式的优点是命中率高,缺点是如果原始数据量大,参数不限定可能使缓存量太大,超过上限,导致缓存失败。因此,该方式适用于不限制参数值查询结果数据量较少,参数变化较多的应用场景。
数据集缓存的保存与更新
数据集缓存的保存
数据集缓存将保存在内存数据库中,使用内存进行保存。
数据集缓存的更新
定期检查缓存最后一次更新时间,如果超过缓存定义中的缓存更新时间,则更新缓存(根据设置的更新方式进行更新)。
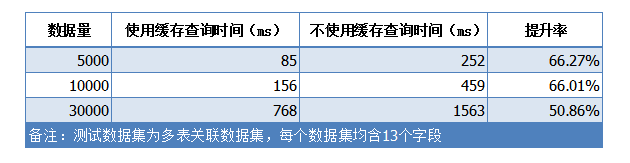
性能提升
数据集缓存通过将数据库中的数据临时保存到应用服务器的内存中,从而减少与数据库交互和发送接收数据的时间。提高平台的响应速度,加快数据集的查询速度。
我们通过一组时间对比图,来了解应用数据集缓存对平台加载数据性能的提升。